by Taylor Walker & Celeste Fremon
California’s voter-approved Proposition 47—which downgraded six low-level drug and property-related felonies to misdemeanors, and thus, reduced the state’s prison population—has been repeatedly accused of having harmed the state’s public safety by causing a spike in crime.
Now, a new study from the University of California, Irvine, suggests that the blame is misplaced.
“Many people assume that since rates for some types of crime went up after the passage of Prop. 47, that it must be the cause, but our study indicates that is not the case,” wrote the team of researchers.
The study’s two authors, Charis Kubrin, professor of criminology, law & society, and Bradley Bartos, a doctoral student in criminology, law & society, at UCI’s School of Social Ecology, explained that theirs is the first systematic analysis to be conducted of the measure’s statewide impact since its 2014 implementation.

Charis Kubrin, UCI professor of criminology, law & society/Patricia DeVoe, UCI
On Friday, the Association of Deputy District Attorneys disputed Kubrin and Bartos’ interpretation of their findings, but we’ll get to that in a minute.
Synthetic California
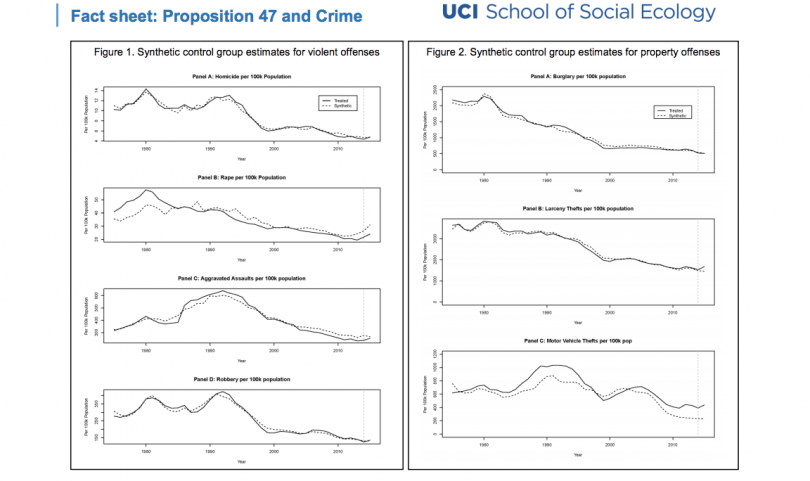
According to Kubrin and Bartos, the problem that analysts ran into previously when attempting to determine whether or not Prop. 47 caused the state’s crime rates to rise, is that they had no “control” against which they could assess how California’s crime rates would have behaved without Prop. 47’s implementation.
To deal with this scientific roadblock, Kubrin and Bartos created what they call a “synthetic California,” which they in turn used as the control for studying crime rates before and after Prop. 47.
To create this synthetic state, the researchers looked at data from the 44 years between 1970 to 2014 (when Prop. 47 kicked in) and then selected with a group of states that experienced crime trends similar to those of California, prior to the end of 2014, when Proposition 47’s effects would have been felt. The combination of these states’ crime rates serve as the “control California,” which the researchers compared with California’s crime rates in 2015, after the passage of Prop. 47.
And what they concluded was that the legislation was not responsible for increases in homicide, rape, aggravated assault, or robbery in California.

Bradley Bartos, Ph.D. student in Criminology, Law and Society, UCI School of Social Ecology
“When we compared crime levels between these two California’s, they were very similar, indicating that Prop. 47 was not responsible for the increase,” Kubrin said.
The researchers did note, however, that property crime trends appear to show Proposition 47 caused an increase in larceny and motor vehicle thefts, “but these findings do not withstand sensitivity and robustness testing,” they wrote.
“What the measure did do,” continued the researchers, “was cause less harm and suffering to those charged with crime. Of course, we want to keep our streets safe, but we also want to be as humane as possible along the way. And it’s good to cut criminal justice costs, especially when that money can be earmarked for crime prevention programs, as some of the money saved by Prop. 47 is supposed to be.”
These initial findings are part of a forthcoming study by Kubrin and Bartos to be published in the Journal Criminology & Public Policy.
Yeah, but which crimes are we talking about?
On Friday morning, the Association of Deputy District Attorneys disagreed firmly with the study’s findings, in the form of a blog post by ADDA’s Los Angeles president, Michele Hanisee. The ADDA made some important points.
First the prosecutors pointed out that although Prop.47 changed the designation for certain low level drug crimes, the study did not consider drug offenses at all.
“Instead, it examined ‘Part 1′ crimes which include homicide, rape, aggravated assault, robbery, burglary, auto theft and larceny.” However, since, Prop 47 only affected the sentencing on drug offenses and larceny offenses (and, to some small degree, auto thefts if the car is valued at less than $950),” the ADDA argued, it was “irrelevant” to consider its impact on “homicide, rape, aggravated assault and the other Part 1 crimes that Prop 47 never addressed.”
We’d like to interject here that Prop. 47 has been blamed by many critics for any and all upticks in crime, including Part 1 crime, but we fully get the prosecutors’ point.
So, what were the results of the study regarding larceny crimes in 2015? “Not surprisingly,” said the prosecutors, “the study showed that ‘Prop 47 did have an impact’ and ‘the larceny effect appears significant.”
Only larceny, wrote the researchers, “appears to have an impact that is large relative to the unidentified variation observed in donor pool states.”
Indeed, while the rest of the crimes that the study looked at, including auto theft, appear unaffected by the ballot proposition. Larceny, however, was, according to the study, although the authors appeared to downplay this part of their findings.
The challenge of determining the causes of crime trends
This new UCI study isn’t the first time that co-author Charis Kubrin, who has studied crime trends for 20 years, has been involved with research pertaining to the effect of California’s reform measures on crime. (Bradley Bartos, a Ph.D. student in criminology, while newer to the study of crime trends, co-authored a leading next on the intriguing synthetic control method.)
In 2016, she co-edited a massive study looking at the effects on public safety of California’s “realignment” prison reform strategy. The study, which was funded in part by the National Science Foundation, was a compilation of work by researchers from a group major California universities, including the Public Policy Institute of California and UC-Berkeley.
The findings—which took up the entire issue of the The Annals of the American Academy of Political & Social Science, which was guest edited by Kubrin and her UCI colleague Carroll Seron—concluded that the state’s prison downsizing strategy put in place by AB 109 had no significant effect on the state’s crime rate, despite many claims to the contrary..
Kubrin spoke to KPCC’s Rina Palta, who reported at the time on the 2016’s study’s release, about the work, which she said back then presented the most comprehensive investigation into the impacts of 2011’s prison realignment to date, and answered the biggest question the reform raised.
“Is California more dangerous as a result of realignment? The answer is ‘no,’ ” Kubrin said..
Now Kubrin’s newest work suggests the same may be true of the often maligned Prop. 47—except maybe in the category of larceny.
POST SCRIPT – You’re not helping
Since we published this story, we notice that the San Francisco Chronicle too did a story on the study, in which they briefly noted the DA’s objections.
The Chron story, which is written by the very smart Bob Egelko, contacted the study’s co-author, UCI Professor Kubrin, and asked her about the ADDA’s objection to her dismissal of the admitted rise in larceny as irrelevant, and not caused by Prop 47.
“Our analysis tells us Prop 47 was not responsible,” Kubrin told Egelko, “so it must have been something else,” such as poverty, inequality, guns or drugs. Kubrin went on to tell Egelko that it was the first systematic analysis of the ballot measure’s effect on crime rates and has been reviewed by top scholars in the field.
Really? Poverty, inequality, guns or drugs???
We are genuinely very grateful to Kubrin, Bartos, and UCI for their fine and innovative research that has gone a long way to counteract the anecdotal, non-fact based criticism, of Prop. 47. However, when the ADDA and Bob Egelko posed a legitimate question about the significant rise in larceny rates after Prop. 47’s passage, a reply “Trust us,” and “all the smart people say we’re right,” or words to that effect, is not sufficient.
No doubt Kubrin and Bartos have a research-based explanation for the larceny numbers. But, if so, they need to be able to explain it to the rest of us who belong to the great unwashed masses out here.
Their failure to do so does harm to the rest of their valuable research.
POST-POST SCRIPT: The researchers reply
On Monday, we heard from UCI professor Charis Kubrin who kindly responded to our criticism. Kubrin thanked us for “bringing attention to this important issue” and directed us to the formal response that she and Bradley Bartos made to the ADDA’S criticism, which you can find in full here.
In brief, however, here are some of the main points that Kubrin and Bartos made.
1. Our study set out to answer one fundamental question: did Prop 47 have an impact on violent and property crime in the year following its implementation? We find that it did not.
2. As we mention briefly in the press release and explain in detail in the paper, our initial model suggests that larceny more than any other offense category may have experienced an increase following Prop 47. However, when we subject this finding to standard post-estimation tests, we are unable to reach a definitive causal conclusion regarding Prop 47’s impact on larceny. In particular, the finding was sensitive to alternative compositions of Synthetic California. Thus, we are unable to reach our goal of identifying a causal effect on larceny.
Or in simpler terms: Yes, larceny went up the year after Prop. 47 but when we subjected that simple finding to further analyses and tests to reveal causality, we could not convincingly attribute the rise to Prop. 47.
For more, please read the UCI research team’s full response.
In any case, we thank Kubrin and Bartos for taking the time to address the questions that we and the ADDA raised.
NOTE: This story was updated on Friday, March 9 at 12:40 p.m., and on Saturday March 10, at 1:20 p.m.—-and Tuesday, March 13, at 1:20 a.m.
O.K.
“…Rates for some types of crime went up after the passage of Proposition 47….”
If Prop. 47 didn’t do it, what did?
Or was that question even investigated?
Also, looking at Dr. Kubrin’s picture I know exactly what her previous job in Criminology was.
T.O. at Firestone Station.
Figures don’t lie, but liars can sure figure. See ,all you have to do is invent a “simulated California” which you can fill with whatever statistics you want (you don’t even have to use California statics, use whatever state you want). Then simply compare reality to your simulation and claim it proves whatever you want. I wonder if climate science is this bogus.
They also fail to inquire how the policies of Crooked James McBuckles against deputies have impacted the proactivity of many of them. LA county is a major producer of criminals and they know deputies are afraid to catch them because of McBuckles policies. There are about 1000 out of about 8000 deputies under investigation by McBuckles, many of those cases are fake and fabricated, yet no justice warrior with a fancy college degree cares to investigate. Deputies lives and carrer don’t matter to this pseudo researchers….
Hmm….a controlled study to support (or refute) a hypothesis conducted by university researchers who are detached, theory-based and have no practical experience versus the opinions of actively working district attorneys and prosecutors who do this everyday for a living? I can tell you who’s opinion has more weight and validly in my humble opinion.
“Those that can do, those that can’t teach.” Although not applicable across the board, spot on in many instances in higher level academia.
How about 2016, 2017, 2018????? What a bogus report.
Irrefutable Fact: Every single crime committed by a person released by Prop 47 and should be in jail at time of said crime, is a crime that was caused by the passage of Prop 47. Add the total crimes committed by those individuals and you have whatever impact they have had on the crime rate.
Does that seem too simple for a Ph.D. thesis?
Joe NoBuckles:
“There are about 1000 out of about 8000 deputies under investigation by McBuckles….”
That’s up from the 400 or so mentioned in this forum just a few months ago.
Has this logjam, I wonder, been cleared up?
http://www.witnessla.com/county-to-look-into-making-it-easier-to-take-action-against-county-employees-who-lie/
Hummm. You lost credibility when you said you indicated you know what someone’s previous job was just by looking at a picture.
Sorry for extra words in my first reply. I meant to say, “Hummm. You lost credibility when you indicated you know what someone’s previous job was just by looking at a picture.”
Prison reform does not make us less safe but it does save us a lot of money on courts, prosecutors, and mass incarceration. Mass incarceration negatively impacts every U.S. citizen by lowering funding for education, infrastructure, public safety, and so on.
Unreasonably harsh, long mandatory sentences are the leading cause of mass incarceration that is practically bankrupting states across the nation.
We must have continued research to ensure we find ways of reducing crime and plugging the school to prison pipeline.
The problem with evaluating Prop 47 is that by making selling drugs and shoplifting – effectively no longer crimes, in my neighborhood alone – every year there are thousands and thousands of no longer reported crimes.
And the true figure likely more in the tens of thousands of now unreported crimes each month – but unless you lived here – you wouldn’t believe those numbers – since the City Attorney refuses to file the cases the police bring him.
But that’s why my relatively small corner drugstore needs three security guards on duty most days. And small shops are moving out of the area and others have to keep tbeir doors locked.
And why has the press not reported the brutal murders and rapes committed by Ptop 47 releases? Because the press doesn’t give a damn. Even when a woman was beaten and tortured and raped over and over again – and then left for dead until she was found tbe next day – still alive – but too weak to survive.
And after we have been filing freedom of information requests for two years to reseach other cases such as this, the number of answered questions we have gotten has been – exactly Zero.
And the woman’s movements have all ignored tragedies such as these. They will even get angry and say that type of activity is NOT what their movement is about.
And that’s why after two years of our nightmare, the number of main stream reporters who have come and seen what Prop 47 has done and written about it – is also exactly zero.
Because we are not what the press wants the public to know about. And the press always does what the powers that be, tells tbem to do.
Pictures speak louder than words.
Thanks for your perspective. You are right: a public light needs to shine on the situation you describe.
Can you provide a link or Google search words for the plight of the woman you mentioned?
Thanks.
Prop 47 affected larceny laws. The California larceny rate goes up near double digits after passage of Prop 47, while falling more than 3% in all other states. And the best the UCI folks can do when their study finds Prop 47 affects the rate is backpedal, claim lack of confidence in their own findings, and then say their were unable to reach their goal of identifying a casual effect on larceny!
Is there a test for common sense at UCI?
Pete:
“Common sense is uncommon.”–Voltaire.
3/14/2018: Just listened to the woman behind this fake “study” on KFI 640 FM (John and Ken Show). As it turns out she’s a social justice warrior with an AGENDA — She’s not any kind of “unbiased researcher”. It is OBVIOUS that prop 47 increased crime. This woman has a liberal ideology of not putting people in prison. Typical liberal Californian hiding behind her bogus “science”.
Just as some are quick to judge law enforcement and paint them as Jack-boot wearing bullies, so it would seem many in higher level academia, politics and the media are enforcing and promulgating a one-sided anti-law enforcement agenda. These professors are teaching our young people their opinions or doctored “facts” while the various forms of media and our politicians are putting out…biased “fake news” reports.
Isn’t this the same type of media/propaganda campaign initiated by Goebels to support the ideology of Hitler and the Nazi regime and numb the masses?
Oh..but no one would dare think “liberal, progressive” thinkers are capable of such a pernicious and diabolical master plan to poison the minds of entries generations.
And you think conservative hacks like the Koch brothers are incapable of a pernicious and diabolical master plan to take over the entire US government at all levels? Look at how much money they’ve spent, and where the money is going. You can assail the usual suspects all you want, and in the meantime the entire store is being ripped off and hauled away…
Ha Ha, yeah that’s what they’re going to do. Nobody will get in their way. No drunk posting should be a rule here Celeste.
If you, “Surefire” can post your rants and diatribe, then any & all other posts gets a pass.
Prove me wrong in any facts I post, all you need to do.
Always sober when I post and on target, that’s why nobody disputes my content, just hate I don’t bend over to you leftist cop hating cowards. F.O.
LATBG, Name one agenda idea or philosophy from the Koch Bros. that threatens the Constitution or implies they want to take over the government.
Now, I could name about 10 each for Ol George Soros. Or any other Leftist for that matter. Their whole agenda is Huge Government and to keep people working on the Plantations……White, Black and Hispanic.
Hell, you Snowflakes even want to tell my how many ounces my Big Gulp can be!! Koch Bros…… Please…… just STFU
What’s wrong LATBG?? Still on Google trying to find something??
Obviously you’re still “butt hurt” since you were taken to task by LATBG in a previous forum & post. Get over it and stay in your lane. Be humble and you won’t get humiliated next time.
Still Laughing; “Stay I My Lane”? While you’re sticking your Fucking nose in someone else’s business? I “Still Laughing” at that.
Remind me when LATBG humiliated me please.
Sorry….. in and I’m
I’ve figured out how to get these Snowflakes to shut the fuck up!!!!!!
All you do is call them out on their bullshit and ask them to present facts!!!
Waaaalllla!! Crickets